|
|
Estimating the actual capacity of a WebSite server requires a variety of different types of analyses. There are many deep, highly technical methods for calculating the capacity of a server to meet imposed load. However, a more practical way is to simply measure the perceived response time accurately, and scale up server capacity to make sure that maximum real-user experiences don't exceed unacceptable delays.
We all have had the exasperating experience of waiting too long for a page to arrive at our Web browser. Ultimately, if the response time is too long, we "click away" and do something else.
Even when the Web is heavily saturated with requests, if you are patient enough every page you request will -- ultimately -- be delivered to your browser. But that's not good enough. Too slow response times turn users away, or, worse yet, because the user has moved on to another page or context, important session data could be lost.
How slow is "too slow"? Jakob Nielsen's figures suggest that after about 7 seconds users "click away". The real answer to "too slow" probably is more subjective, but at the same time probably not too terribly different. In other words, the WebSite sever is configured properly and effectively when it has "enough capacity to meet the customer demands."
There is very good software available that will indicate how many URLs are being requested per second, and how many bytes are downloaded per second. If you know the server machine capability you could average these figures and estimate accurately if the average capacity to deliver pages exceeds the average demand. But this leaves unanswered the key question: What will the peak load be?
But if the WebSite involves a two-tier or three-tier structure -- which is increasingly common for e-commerce sites -- then measuring one machine may lead to false conclusions. For example, all three machines in a three-tier structure could be achieving their performance goals -- that is, not setting off alarms -- but the overall cumulative application could still be "too slow" to satisfy users.
Even though it is relatively easy to measure if such tests run slower than a threshold -- for example, the 10 second overall response time limit -- this approach has a fundamental limit: it is only as good as the set of scenarios that you develop to emulate actual WebSite use.
Many factors affect how fast a WebSite appears to a user. There are many, many stages between a RETURN typed on a browser and a completed [or complete enough] page being rendered on the client.
Note: An apology is due for the simplifications here. In fact, the sequence is rather more complex because all of the machines along the way between a request by a browser and a response seen in the browser involve, typically, multi-programming, multi-threaded executions that dynamically adapt to changing Web conditions that are at least in part adjusting to the actual requests that are being discussed. Left out are such technologies as threading requests via different routs, packet re-transmits and asynchronous arrivals, and much LAN protocol complexity.
Still, the bottom line is clear: elapsed time perceived by the user actually occurs, as they say, in true real time.
The main goal of creating an artificial load to impose on a WebSite is to permit the load to emulate one or a dozen or a hundred or thousands of users actually using the WebSite. There are two main ways to do this. Caveats: On the Web, this may be quite difficult. On the LAN this is easier, but may require a 100Mbps LAN to saturate the servers. Hope: At some point the capacity will scale linearly: 2X machines means 2X capacity.
While relatively easy to use to generate basic retrievals of pages, this approach suffers from the fact that all of the URLs associate with a page have to be included if the simulation is to be a realistic one. The disadvantage is that you could easily create a test scenario that fails to include important load factors such as download times for images and other slow-to-respond page components.
We can now outline a basic experiment format that provides a high level of realistic loading of a candidate WebSite server using eValid's unique client-side browser based testing technology. The goal of each experiment is to determine the ability of the subject WebSite to sustain load from a varying number of realistic simulated users. Generally this goal is obtained if we can develop a set of response-time curves that illustrate typical average response times from the server via the Web, as a function of WebSite load that has been imposed.
To make the overall test scenario as realistic as possible these recorded tests should include:
After recording we make sure each test script is self-restoring, that is, we make sure that running the test script multiple times will not perturb the WebSite being measured in a way that will affect the results. This is a relatively common attribute of a regression test and may involve the use of test accounts or special logins that avoid irreversible second-tier or third-tier database moves.
At this point we can calculate, for each test script, the load each script represents in terms of the total number of URLs involved and the size [or average size] of the URLs retrieved. From this we can make basic estimates of the URLs/sec and KBytes/sec that might represent a serious load on the candidate WebSite.
The bandwidth from the machine or machines running the scenario affects the meaningfulness of the tests. The bandwidth available from the test machines to the WebSite being tested should be large enough that the duty cycle does not exceed 50%.
PC's with large enough memory and high-enough speed access, e.g. T1 or T3, may have to be identified for large experiments.
Guidelines for scenario design include:
This planning should be done in advance insofar as possible because the higher loadings will likely involve use of substantial resources. For example if we are testing a high-capacity site, capable of 1000's of simultaneous users, then the tests will have to consume the corresponding amount of bandwidth.
This fact is important because if you load up a site with 1000's of users using eValid playbacks ultimately, depending on the server capacity and the bandwidth of the pipeline to the client, all of the requested pages will, ultimately, be downloaded successfully. Hence, the only really effective measure of the capacity of a Web server is how fast it succeeds in delivering pages to your client, relative to how fast it could do that if the server and the intervening Web infrastructure were all infinitely fast. This time is called the unloaded performance time or the base performance time.
A very simple way to establish a measurable capacity criteria for your Web server is to require that the slowest overall test time -- i.e. the overall test time for a script in the heaviest load that you expect the server to have -- is always below some multiplier over the base performance time. A good, practical measure you can set in advance for this is 2X or 3X or 4X or even 5X.
This figure is called the server slowdown value. It is a fixed value that your server must never exceed for a specified server capacity. If you choose, for example, a 2X factor, that means your server will be judged to be at 2X server capacity when the average download time of a particular scenario is no more than 2 times as long as the base performance time.
The first part is to establish the base performance time for a very lightly loaded server. After this is established, the tests are run up in stages to the target maximum load. The average response time is measured in each successive stage.
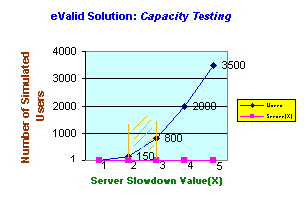
While the issues of measuring WebSite server capacity are many and complex, what becomes clear is that users' perception of effective, useful response time is the dominant factor in assuring adequate capacity. This can be accomplished by realistic browser-based experiments that measure aggregate response time as a function of gradually increased parallelism.